
Machine Learning
Machine learning is the science of teaching a computer to recognize unique patterns in data without being given a specific instruction manual for every task. This process is comparable to teaching the identification of ripe fruit where, instead of a rigid book of rules regarding color or texture, a system is presented with numerous positive and negative examples until the underlying logic is mathematically established. Machine learning performs this exact process with digital information by ingesting thousands of data points, such as customer purchase histories or linguistic nuances, so the internal architecture can identify correlations and provide an accurate inference for new, unseen data.
Key Takeaways
- Machine learning is a subset of AI that allows computers to learn from data experience rather than explicit programming.
- The traditional programming model is flipped: instead of humans providing rules, the machine discovers the rules by analyzing inputs and outputs.
- Success depends on a structured seven-stage pipeline, starting with high-quality data collection and ending with continuous monitoring.
- There are four primary learning paradigms: Supervised, Unsupervised, Reinforcement, and Semi-supervised learning.
- Deep learning uses neural networks to handle unstructured data like images and voice, moving toward more autonomous “black box” logic.
- Python is the industry-standard language, supported by powerful frameworks like TensorFlow and PyTorch.
What Is Machine Learning?
To define machine learning is to recognize a fundamental shift in computational philosophy. Traditionally, a computer required Inputs + Rules to generate an Output. In machine learning, this script is flipped, and the system is provided with Inputs + Outputs, and the algorithm itself derives the Rules.
“Machine Learning is the field of study that gives computers the ability to learn without being explicitly programmed.” — Arthur Samuel, 1959
Arthur Samuel, an IBM pioneer, substantiated this theory by developing a program to play checkers. The computer was not instructed on every possible move; instead, it engaged in thousands of matches against itself, identifying which board positions statistically led to a victory.
Today, machine learning is viewed through three distinct analytical lenses:
- Data serves as the raw material and the fundamental fuel for the system.
- Patterns are the hidden relationships and structural regularities discovered within that data.
- Experience is the iterative process of making a prediction, measuring the error, and refining the mathematics to improve future performance.
Machine Learning vs Artificial Intelligence vs Deep Learning
While these terms are frequently used interchangeably, they represent nested layers of a much broader technological vision. Understanding the hierarchy is essential for proper implementation.
Artificial Intelligence (AI) serves as the “Grand Umbrella.” It encompasses any technique that enables computers to mimic human behavior, ranging from the symbolic logic of 1980s “Expert Systems” to modern autonomous robotics.
Machine Learning (ML) is a specialized discipline within the AI field. It refers specifically to the use of statistical methods that allow a system to improve at a task through exposure to data rather than manual programming.
Deep Learning (DL) is a high-performance toolkit within the ML domain. It utilizes Artificial Neural Networks—layers of mathematical functions inspired by biological brain structures—to solve high-complexity problems such as facial recognition or real-time language translation.
| Feature | Artificial Intelligence (AI) | Machine Learning (ML) | Deep Learning (DL) |
| Scope | The broad goal of creating “smart” machines. | A method for achieving AI through data. | A high-performance technique within ML. |
| Dependency | Can be rule-based (no data needed). | Heavily dependent on structured data. | Requires massive “Big Data” and GPUs. |
| Human Effort | High (programmers must define logic). | Medium (humans select “features”). | Low (the model discovers features alone). |
| Logic | Often transparent (If-Then rules). | Statistical and mostly interpretable. | “Black Box” (highly complex logic). |
Why Machine Learning Is Important Today
Machine learning existed as a mathematical theory for decades, yet it remained largely theoretical until the modern era. Three major technological drivers have recently transformed this theory into a global operational reality:
- The Big Data Explosion: The daily generation of quintillions of bytes of data provides the volume necessary for statistical significance. For a retailer, every click, cart addition, and return serves as a training observation. Machine learning thrives on this scale; the more data ingested, the more refined the model becomes.
- The GPU Revolution: Traditional central processors are designed for sequential tasks. In contrast, Graphics Processing Units (GPUs) can handle thousands of simultaneous calculations. This parallel processing capability provides the exact computational “heavy lifting” required for neural networks to function efficiently.
- The Cloud & Accessibility: The requirement for multi-million dollar on-site server rooms has been replaced by cloud infrastructure. Platforms such as AWS, Google Cloud, and Azure allow organizations to rent high-level computational power on demand, making sophisticated modeling accessible to entities of all sizes.
The Business Value
In the retail sector specifically, the importance of machine learning lies in the transition from Reactive operations to Proactive strategy. By adopting these models, organizations move beyond analyzing last month’s sales to predicting next week’s demand. This gains a “computational intuition” that identifies market opportunities and logistical risks that remain invisible to human observation.
How Machine Learning Works
The transformation of raw digital signals into a predictive asset is a structured, seven-stage process. For any enterprise, the resilience of the model depends entirely on the integrity of the underlying pipeline.
Data Collection
The process originates with the systematic aggregation of raw information. In a retail environment, this involves centralizing disparate data streams such as point-of-sale transactions, website clickstream metadata, and inventory fluctuations. Because the algorithm derives its logic solely from this evidence, the breadth and quality of the initial intake dictate the eventual ceiling of the model’s performance.
Data Preprocessing
Raw data is inherently disorganized and often contains statistical noise. This stage involves the clinical cleaning of the information, where null values are handled and statistical outliers are removed. Standardizing numerical scales is also necessary to prevent the model from becoming biased toward larger ranges. This preparation ensures the mathematical foundation is stable and free from the “garbage in, garbage out” failure common in poorly managed projects.
Feature Engineering
At this stage, specific variables known as features are identified for their predictive power. In a demand-sensing model for clothing, for instance, localized weather patterns may be a high-impact feature, whereas a customer’s transaction ID is discarded as irrelevant noise. Selecting the most influential features requires an analytical understanding of which data points actually correlate with the desired business outcome.
Model Training
During training, the algorithm is exposed to the prepared data to establish a mathematical fit. The system makes iterative predictions and calculates the distance from the truth using a loss function. The internal weights of the model are adjusted repeatedly to minimize this error, effectively allowing the system to refine its own internal rules through sheer computational repetition.
Model Evaluation
Once the training phase is complete, the model must be validated using a hold-out dataset that was not part of the initial training. This test determines if the system can generalize its logic to entirely new scenarios. If the accuracy remains high, the model is considered robust; if it fails, it has likely suffered from overfitting, meaning it memorized specific past examples rather than learning the broader underlying pattern.
Deployment
Successful models are integrated into the live production environment. This transition allows the model to process real-time data and return immediate results, such as generating dynamic discount codes or optimizing supply chain routes. The deployment must be seamless to ensure the model can handle high-velocity data without increasing latency for the end user.
Monitoring
The final stage is the ongoing observation of the model’s performance. External factors and shifting consumer habits can cause concept drift, where the model’s accuracy slowly decays as the world moves away from the conditions of the original training data. Continuous monitoring is the only safeguard that ensures the system remains an accurate and profitable asset over the long term.
Types of Machine Learning
The selection of a learning paradigm is the most critical architectural decision in a project. The choice is governed by the nature of the available data and the specific complexity of the problem.
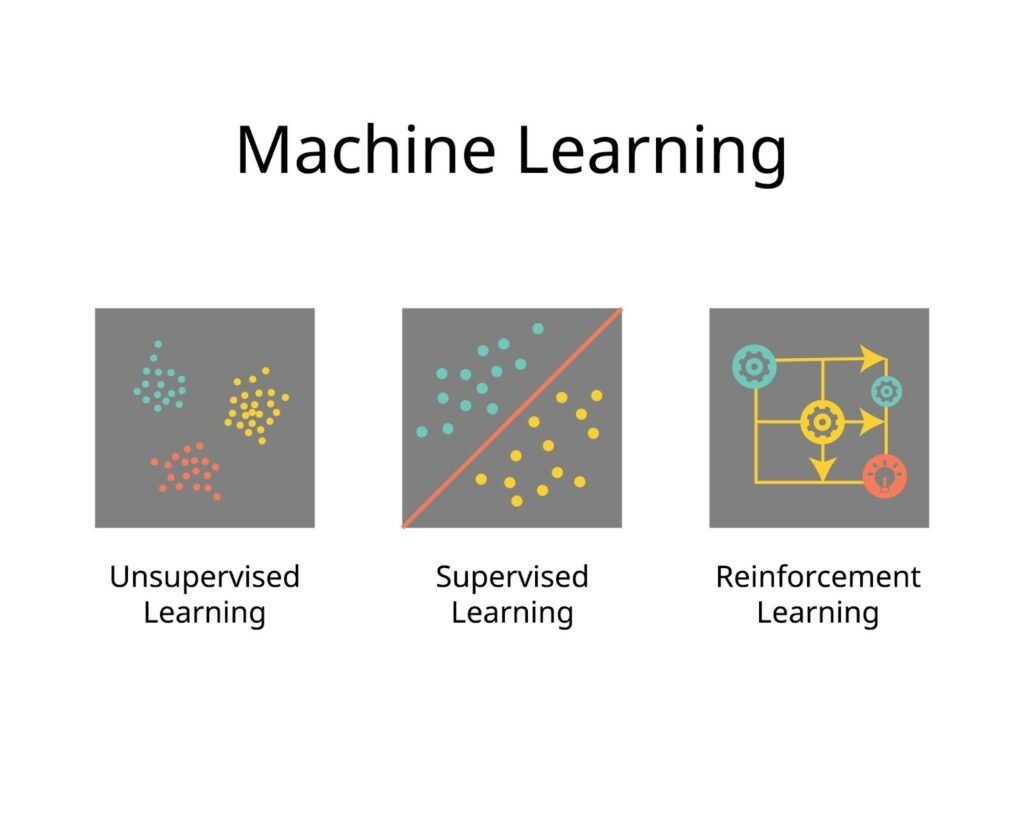
Supervised Learning
Supervised learning is defined by the use of a labeled dataset. In this framework, the machine receives inputs that are already paired with the correct target outputs. The mathematical objective is to learn the function that maps these inputs to the labels provided in the training set.
This logic is fundamental to several key operations:
- Spam Detection: Large volumes of emails already identified as “junk” or “safe” are processed until the model recognizes the linguistic hallmarks of spam autonomously.
- Price Prediction: Historical markdown data serves as the ground truth for estimating the future market value of new inventory.
- Medical Imaging: Algorithms are trained on thousands of scans previously labeled by specialists to identify early indicators of pathology.
Unsupervised Learning
This paradigm involves the processing of unlabeled data where no pre-defined categories exist. The algorithm is tasked with finding hidden structures or Clustering patterns based on the natural distribution of the data. The system identifies similarities between data points, allowing for the discovery of groupings that may not be apparent to a human analyst.
This is a primary tool for deep market analysis:
- Customer Segmentation: The model analyzes variables like purchase frequency and dwell time to reveal natural clusters of shoppers without any prior classification.
- Association Discovery: This technique uncovers hidden relationships in data, such as identifying that certain product categories are statistically likely to be purchased together.
Reinforcement Learning
Reinforcement learning is a goal-oriented process where an autonomous agent learns through trial and error. The system is placed within an environment and must take actions to maximize a specific “reward” signal. The optimal strategy is developed by experiencing the consequences of millions of different decisions rather than following a static dataset.
The impact of this method is most visible in complex, dynamic systems:
- Robotics: Mechanical systems in logistics centers learn the most efficient movement patterns by reinforcing the actions that lead to a successful task completion.
- Game Intelligence: Systems achieve mastery by playing against themselves and prioritizing the moves that statistically lead to a victory.
- Dynamic Logistics: Algorithms learn to adjust shipping routes or pricing in real-time to find the most cost-efficient path based on environmental feedback.
Semi-Supervised Learning
In many enterprise scenarios, the cost of labeling every data point is prohibitive. Semi-supervised learning utilizes a small, expertly labeled “seed” dataset to guide the interpretation of a much larger pool of unlabeled information. This hybrid approach allows for high-level predictive accuracy while significantly reducing the time and resources required for manual data preparation.
Common Machine Learning Algorithms
Selecting a specific mathematical framework is a high-stakes decision driven by the dimensionality of the dataset and the nature of the business objective. An expert must evaluate these machine learning tools based on their inherent logic and their ability to solve distinct structural hurdles.
Linear Regression
This remains the definitive machine learning method for predicting continuous numerical variables. It establishes a linear relationship between features to forecast specific values. In a corporate setting, this serves as the standard for sales forecasting. For instance, a retail analyst uses this machine learning approach to determine how a 10% increase in marketing spend correlates with gross revenue.
Logistic Regression
Despite the name, this is a machine learning classification tool rather than a standard regression. It calculates the probability of an input belonging to a specific category. If a financial institution needs to determine the likelihood of a transaction being a default, this machine learning algorithm maps the inputs into a range between 0 and 1 to create a clear threshold for risk assessment.
Decision Trees
A decision tree functions as a strategic map of branching conditions where each node represents a test on a specific attribute. This type of machine learning provides a transparent, white-box logic for complex choices. It is highly valued for its ease of audit in regulated industries like insurance where the machine learning path to a specific approval or denial must be documented.
Random Forest
To mitigate the instability of a single tree, which is prone to memorizing statistical noise, a random forest is employed. This ensemble machine learning technique initiates hundreds of individual trees where each is trained on a different subset of data. The final output is determined by a majority vote across the forest. This machine learning approach ensures the system is resilient to statistical outliers and high variance.
Support Vector Machines
These machine learning models are implemented when the boundary between categories is complex and non-linear. The algorithm identifies an optimal hyperplane that maximizes the margin between different classes in a high-dimensional space. It is a primary machine learning choice for bioinformatics such as identifying protein structures or classifying complex genomic data.
K-Nearest Neighbors
This machine learning algorithm operates on the principle of spatial proximity. It assumes that similar data points exist in close groups. To classify a new entry, the machine learning system looks at the closest examples in the environment. If the majority of a shopper’s neighbors purchased premium goods, the system infers that the new shopper will likely follow that pattern.
Naive Bayes
This is a probabilistic machine learning classifier based on the assumption that all input features are independent. Because it is computationally light, it provides rapid classification for massive text volumes. It is the industry standard for machine learning applications like sentiment analysis and real-time spam filtering where thousands of words must be categorized in milliseconds.
Neural Networks
These represent the most complex tier of machine learning algorithms consisting of interconnected layers of mathematical nodes. They excel at identifying non-linear patterns in massive, unstructured datasets. These machine learning systems are uniquely capable of handling raw data types like audio and video, serving as the foundational architecture for advanced autonomous applications.
Deep Learning and Neural Networks
Deep learning is a specialized branch of machine learning that utilizes multi-layered architectures to automate feature extraction. Unlike traditional machine learning methods, these systems identify their own relevant patterns directly from raw data without manual human intervention.
The core structure of these machine learning models involves an input layer, several hidden layers, and an output layer. As data flows through these nodes, the machine learning system assigns weights and biases to different signals to reinforce the pathways that lead to correct predictions.
For visual tasks, Convolutional Neural Networks (CNN) serve as the primary machine learning engine. They utilize mathematical filters to detect local patterns, starting with simple edges and moving toward complex objects like faces. For sequential data, Recurrent Neural Networks (RNN) maintain a form of memory where the output of one step informs the next, making them ideal machine learning tools for speech recognition.
The machine learning industry has largely transitioned toward the Transformer architecture. Transformers use a self-attention mechanism to process entire sequences of data simultaneously. This allows the machine learning model to understand the context of a word based on its relationship to every other element in the set, which is the intelligence behind modern language models.
Real-World Applications of Machine Learning
The transition from mathematical theory to industrial value is evident across every major sector. These applications demonstrate how machine learning provides a level of operational scale that human oversight cannot match.
Healthcare
Machine learning assists in disease detection by scanning thousands of medical images for anomalies that might be invisible to a fatigued radiologist. In oncology, these machine learning systems identify cellular irregularities with high statistical consistency. Beyond imaging, machine learning models analyze patient history to identify early markers of chronic conditions.
Finance
Financial institutions deploy machine learning models as a real-time defense layer. When a credit card is swiped, a machine learning fraud detection model analyzes the transaction against a behavioral baseline. If a high-value purchase occurs in a foreign city, the machine learning system can intervene in milliseconds to prevent capital loss.
Retail
Modern retail thrives on machine learning recommendation systems. By analyzing the latent factors in a user’s history, the machine learning system suggests products with a high probability of conversion. This personalization moves the needle from showing a catalog to anticipating a need, increasing customer engagement through machine learning.
Transportation
The development of self-driving cars relies on a fusion of visual navigation and machine learning reinforcement learning for decision-making. These systems process environmental data in milliseconds to navigate traffic and identify pedestrians. Machine learning is also used in aviation to optimize flight paths to reduce fuel consumption.
Marketing
These machine learning technologies enable hyper-precise customer targeting. Rather than broad demographic broadcasting, the machine learning system identifies the specific individuals most likely to respond to a campaign or those at risk of leaving a service. This machine learning strategy ensures that marketing budgets are spent on individuals with the highest statistical likelihood of response.
Cybersecurity
Modern threat detection systems use unsupervised machine learning models to establish a baseline of normal network behavior. Any intrusion attempt is flagged as a deviation from this norm. This allows the machine learning system to quarantine suspicious traffic before a zero-day exploit can result in a breach.
Advantages of Machine Learning
Traditional software acts as a rigid instruction manual that only knows what is explicitly programmed. Machine learning represents a fundamental move toward computational “intuition” capable of handling complexity beyond manual human intervention. Several core benefits define the strength of this approach:
Processing High-Dimensional Data involves identifying non-linear relationships across thousands of variables simultaneously.
Autonomous Improvement utilizes feedback loops where every new piece of data serves as a fresh lesson to sharpen accuracy.
Handling Unstructured Information allows for extracting meaning from messy data formats like natural language, audio, and video streams.
Rapid Decision Velocity is achieved by analyzing signals and executing responses in milliseconds for high-frequency environments.
Personalization at Scale enables the tailoring of unique experiences for millions of individual users at the same time.
Challenges and Limitations
Machine learning is not a flawless solution, and an expert implementation requires a clinical understanding of the technical friction points that can degrade a model’s integrity.
- The Risk of Algorithmic Bias: A machine learning model is a mathematical echo of its training data. If the input contains historical prejudices or skewed demographics, the algorithm will reinforce those biases. For instance, a model trained on a narrow subset of the population may fail to generalize or produce unfair outcomes when applied to a broader, more diverse group.
- The Interpretability Gap: High-performance systems, particularly deep learning architectures, often operate as “Black Boxes.” While the output may be highly accurate, the internal mathematical complexity makes it difficult for humans to explain why a specific decision was reached. This remains a significant barrier in high-stakes fields like medicine or autonomous transport.
- Data Dependency and Quality: The “garbage in, garbage out” principle is amplified in machine learning. A model is entirely dependent on the quality and volume of its training data; without a massive, clean, and representative dataset, the resulting model will be statistically fragile and prone to error.
Tools and Frameworks Used in Machine Learning
The modern machine learning stack is built on a foundation of open-source libraries that handle complex mathematical operations. This architecture makes the field accessible to anyone with basic programming knowledge. Python is the undisputed language of the field, acting as the primary interface for specialized libraries. Within this ecosystem, Pandas handles data cleaning and restructuring, while Scikit-learn provides the standard toolkit for classical algorithms like Decision Trees and Random Forests.
For building deep neural networks, two primary frameworks dominate the industry:
- TensorFlow: Developed by Google, this powerhouse is built for industrial-scale deployment and massive production pipelines.
- PyTorch: Created by Meta, this framework is favored by researchers for its flexibility and ease of debugging during experimentation.
Machine Learning vs Traditional Programming
The transition from traditional software to machine learning involves a philosophical shift from top-down logic to bottom-up discovery. In Traditional Programming, a human provides the Data and the Rules. The computer follows these instructions to produce the Output. This remains effective for predictable tasks with clear, unchanging logic, such as a basic calculator.
In contrast, the logic in Machine Learning is inverted. The computer is provided with the Data and the Output, and the machine learning process then works backward to figure out the Model. These are the mathematical rules that connect the data to the result.
Ultimately, this shift enables the resolution of previously un-programmable problems. Tasks like real-time translation or autonomous vehicle navigation are too complex for a human to write down every individual rule manually, making the discovery of patterns through data the only viable path forward.
Future of Machine Learning
The trajectory of machine learning suggests a shift from static tools toward autonomous intelligence. As mathematical frameworks stabilize, the focus moves toward how these systems interact with the physical world and how they can be built more efficiently.
Generative AI represents a pivot from simple classification to the actual creation of new content. By leveraging massive datasets, these models synthesize text, images, and code that mimic human output with accuracy. This evolution is giving rise to AI Agents. These are systems designed not just to answer questions, but to execute multi-step tasks autonomously. An agent might research a topic, draft a report, and email it to a team by navigating various software interfaces without constant human prompting.
To make these complex systems more accessible, AutoML is transforming the development pipeline. These tools automate labor intensive parts of building a model such as selecting the right algorithm or tuning internal parameters. This allows experts in fields like biology or economics to apply high level intelligence without a deep computer science background.
Simultaneously, Edge AI is pushing intelligence out of massive data centers and directly onto local hardware. By running optimized models on smartphones, medical wearables, and industrial sensors, systems process data instantly and securely.
How to Start Learning Machine Learning
Entering this field requires a balanced approach between theoretical mathematics and practical implementation. Because the technology moves rapidly, focusing on fundamental principles ensures long term competence rather than just memorizing software syntax.
A baseline understanding of Math Basics is the first essential step. Machine learning is applied statistics. One must understand how a model weights variables to truly debug a failing system. Linear Algebra, Calculus, and Probability form the core of this knowledge. Following the math, Python mastery is the priority. Python acts as a glue for specialized libraries like NumPy and Pandas which are essential for data manipulation.
Theory only sticks when applied to Datasets. Engaging with platforms like Kaggle allows learners to access open data and simulate professional challenges. Moving a concept from initial data cleaning to a live, functioning model is the most effective way to prove competence. This project based approach ensures that the nuances of the machine learning pipeline are fully understood.








